


반응형

위처럼 오류 메시지가 뜰경우 취소 버튼 클릭 후 도구 -> 옵션 선택
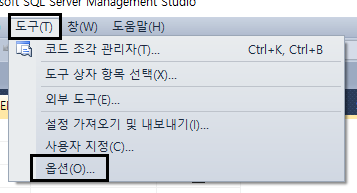

위처럼 테이블 및 데이터베이스...의 테이블 옵션에 들어와서 테이블을 다시 만들어야 하는 변경 내용 저장 안 함을 체크 해제 한 후 확인 버튼 클릭하고 다시 저장을 해보면 잘 된다.
반응형

우주의빛
자료를 공유하고 좋은자료 추천 하는 곳입니다.
위처럼 오류 메시지가 뜰경우 취소 버튼 클릭 후 도구 -> 옵션 선택
위처럼 테이블 및 데이터베이스...의 테이블 옵션에 들어와서 테이블을 다시 만들어야 하는 변경 내용 저장 안 함을 체크 해제 한 후 확인 버튼 클릭하고 다시 저장을 해보면 잘 된다.
우주의빛
자료를 공유하고 좋은자료 추천 하는 곳입니다.
MSSQL에서 함수를 만들어 사용하는데
그 함수를 사용하는 쿼리문의 문제가 발생한다면...
.NET Framework에서 사용자 코드를 실행할 수 없습니다. "clr enabled" 구성 옵션을 설정하십시오.
위처럼 에러 메시지가 뜰 경우
SQL Management Studio로 해당 DB에 접속해서 clr을 활성화 시켜줘야 한다.
EXEC sp_configure 'clr enabled', 1
RECONFIGURE
위처럼 입력하고 실행을 하면
"1로 변경했습니다."라는 메시지가 뜨고 함수가 있는 쿼리문을 다시 실행시키면
정상적으로 실행이 됩니다.
우주의빛
자료를 공유하고 좋은자료 추천 하는 곳입니다.
가끔 테이블의 전체 Row수를 가져와야 할 경우 어떤것이 더 좋은지를 설명하겠습니다.
제가 처음에 MS-SQL을 사용할 때 "select count(*) from table명" 이렇게 사용했습니다.
한 몇천개 데이터가 있는 곳에서는 전혀 문제가 안됬죠...
근데 데이터가 쌓이다 보니.. 문제가 발생
count(*) -> count(0)으로 하면 좋습니다.
*라고 하는 건 모든것을 의미합니다. 테이블의 모든부분을 보기 때문에 아무리 컴퓨터라도 시간이 걸릴 수밖에 없죠 0이라고 하는건 첫번째 즉 첫번째 열만 보게 되기 때문에... 모든걸 보는것보다는 빨라지죠...
근데.... 데이터가 더더더 많이 쌓이게 된다면???
요즘은 빅데이터다 보니...
테이블에 5천만건이상의 데이터를 넣어봤습니다.ㅎㅎ
select count(0) from tb_test -> 총 시간이 4분 이상 걸렸죠...
이러면... 나라도 그냥 홈페이지 끄고 다른곳으로 갈 것 같습니다...
커피 한잔을 마실 수 있는 시간이니까요..
SELECT DISTINCT MAX(A.rows)
FROM SYSINDEXES AS A
INNER JOIN SYSOBJECTS AS B ON A.id = B.id
WHERE B.type = 'U' and B.name = 'tb_test'
위와 같이 쿼리를 만들어서 실행한결과...... 0초...
5천만건 0초!!!!ㅎㅎㅎㅎㅎ
데이터는 모두 날린 상태라 스크린샷은 없지만...
정말 유용할 것 같은 쿼리입니다.
우주의빛
자료를 공유하고 좋은자료 추천 하는 곳입니다.
자료를 공유하고 좋은자료 추천 하는 곳입니다.
